Dissenyant un model computacional de la mà d’Ignasi De Pouplana, líder del repte 4

El repte 4 de PIKSEL desenvolupa un model computacional per a la diagnosi i la predicció d’episodis de contaminació per NO2 a Catalunya, concretament al Camp de Tarragona i Barcelona.
Avui ens acompanya el líder del repte i investigador postdoctoral del, Ignasi De Pouplana, que ens explica com s’ha desenvolupat aquesta eina de PIKSEL, com neix la idea del seu disseny i les dificultats que ha hagut de superar l’equip del repte per aconseguir un model computacional original i innovador.
Avui ens acompanya el líder del repte i investigador postdoctoral del Centre Internacional de Mètodes Numèrics a l’Enginyeria (CIMNE), Ignasi De Pouplana, que ens explica com s’ha desenvolupat aquesta eina de PIKSEL, com neix la idea del seu disseny i les dificultats que ha hagut de superar l’equip del repte per aconseguir un model computacional original i innovador.
Què és el més rellevant d'aquest repte?
El més important és l'objectiu d’aconseguir una eina que doni una resposta a curt termini, perquè estem parlant de prediccions de la contaminació per NO2 d’un, dos o tres dies. En l’àmbit computacional això és una resposta bastant ràpida, perquè hi ha càlculs que poden trigar setmanes. Volem tenir informació sobre NO2 o quantificar-ne concentracions en un temps relativament curt, amb una àrea d’interès bastant àmplia, però que alhora sigui prou local.
Si ho obtenim, es podrà partir d’aquesta informació a l'hora de prendre decisions sobre la gestió del trànsit o altres causants d'emissions.
Quins són els referents de l’equip del repte? Hi ha algun altre centre de recerca o empresa que desenvolupi un model semblant?
Si ens hem de comparar, podem parlar de dos models: el FEMAC i el FLEX, tot i que n’hi ha un gran nombre. Molts d’aquests models s’apliquen a macroescala, pràcticament a nivell de Catalunya i Espanya. Després hi ha el del Barcelona Supercomputing Center (BSC), que treballa amb un model ambiental en una escala bastant gran.
Així doncs, es tracta de models de macroescala més paramètrics i que no discretitzen un domini concret, com estem fent nosaltres, dels carrers de Barcelona.
A quina necessitat respon el repte? Com es va originar?
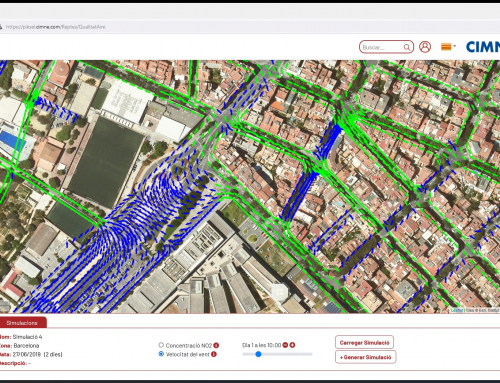
Posem per cas que necessitem quantificar les concentracions de NO2 a escala de carrer d’una zona urbana com Barcelona, o com Tarragona, o qualsevol altra ciutat, i ho volem determinar a fi de poder prendre mesures locals de restricció del trànsit a nivell de carrers concrets. Doncs bé, aquesta eina tan concreta avui dia no existeix, i el repte respon a aquesta necessitat.
També hi ha l’altre extrem, que és anar-se’n a models d’elements finits (per exemple, de molt de detall en 3D) amb els quals descriure una secció de carrer perfectament, amb la turbulència del vent, la temperatura de l’asfalt, és a dir, amb tot el que vulguis. Aquests models permetrien incorporar i transportar el contaminant amb molt de detall, però a l’hora d'aplicar-los a diversos carrers no serien pràctics, serien caríssims i trigarien molt de temps a donar una resposta.
Es tracta d’una eina que mesura la contaminació a petita escala. No hi ha, ara mateix, cap altre enfocament com el vostre, en altres llocs?
No, jo crec que és bastant original.
“Això és l’ABC del model de simulació numèrica: el resultat que et dona la simulació dependrà del model i de les dades d'entrada.”
“Això és l’ABC del model de simulació numèrica: el resultat que et dona la simulació dependrà del model i de les dades d'entrada.”
Quins van ser els primers passos per desenvolupar del repte?
Estàvem acabant la tesi doctoral de l’Albert Puigferrat i sabíem que per predir els contaminants de l’aire, si te’n vas a un detall molt gran amb 3D, has d’estimar les dades d’entrada: a cada hora, l’emissió de NO2 depèn del trànsit, com t’ho inventes? Quina temperatura li poses?
Tot això són dades que han d’alimentar el model i, si no en tens ni idea, el model ja pot ser tan precís com vulguis, que pot donar qualsevol cosa com a resultat.
La reflexió era: quin sentit té fer un model amb tant de detall, que sabem que és car, si les dades que tenim d’entrada són una incògnita? Això és l’ABC del model de simulació numèrica: el resultat que et dona la simulació dependrà del model i de les dades d’entrada.
Per això vam anar a fer el model que estem fent i estudiant ara: un plànol de la ciutat amb els carrers i les illes de cases en dues dimensions. I simplificant molt el que és el vent i altres efectes existents, perquè n’hi ha molts que no els estem tenint en compte.
Però si podem aconseguir que aquest model –calibrant-lo una mica i validant-lo, òbviament, amb les estacions de mesura que tenim– reprodueixi el que nosaltres volem, encertant l’ordre de magnitud, s’aconsegueix una informació molt rellevant perquè ens permet calcular molt de pressa. Sobre aquest model podem anar afegint cosetes amb el temps, fent-lo més precís. Es tracta d’anar incorporant petites complicacions que poden encarir el model.
“Es comença directament amb alguna cosa més senzilla, i sobre això vas construint i optimitzant l'ús del model."
“Es comença directament amb alguna cosa més senzilla, i sobre això vas construint i optimitzant l'ús del model."
El que no podem fer és començar un model que trigui una setmana a donar-nos un resultat, perquè ja d’entrada no ens serveix. Es comença directament amb alguna cosa més senzilla, i sobre això vas construint i optimitzant l’ús del model. Així pots millorar certs aspectes amb el marge que tinguis de temps.
Perquè cal estar tota l’estona vigilant el temps: al final aquests problemes tenen milers de graus de llibertat, i triguen un temps a calcular-se.
El model computacional que heu dissenyat incorpora equacions per calcular el transport del contaminant NO2 a través de l’aire: com vau escollir les equacions més adients per a aquest model?
En el plànol vam començar provant diferents models: l’equació de shallow-water s’aplica a aigües poc profundes i és una simplificació de les equacions de Navier-Stokes amb mitjanes segons alçada.
El model de Navier-Stokes, d’altra banda, es fa servir per al transport d'onatge a gran escala, però aquestes ones a nosaltres no ens interessen. En el nostre cas no hi ha aigua, així que s'hauria d'haver complicat molt el model de shallow-water perquè dona molts problemes de reflexió d'ones, i per això el vam descartar.
Llavors vam provar les equacions de Navier-Stokes directament, és a dir, en dues dimensions sense cap simplificació. El que passa és que les equacions de Navier-Stokes, amb les condicions de vent que tenen les ciutats, on el vent bufa bastant i apareixen efectes turbulents, tridimensionals, tampoc servien.
Aquesta turbulència aportava inestabilitats al càlcul en un model que era 2D, i per això no tenia gaire sentit continuar aplicant aquesta equació.
Aleshores vam optar per l'equació de flux potencial.
L’equació de flux potencial considera un flux laminar amb uns contorns, és a dir que, si tenim una illa de cases, l’aire passa al voltant d’aquests edificis. És una simplificació molt gran, però vam veure que ens donava una resposta bastant ràpida i robusta, amb una certa precisió, sense inestabilitats i de l’ordre de magnitud que esperàvem.
D’aquesta manera, la velocitat que s’obté amb les equacions de flux potencial al voltant dels carrers la fem servir en l’equació de transport per transportar el contaminant.
Així és la metodologia que hem dissenyat finalment.
Si disposéssiu de recursos il·limitats i/o col·laboracions amb altres entitats, què us agradaria que aconseguís el repte en l'àmbit tècnic? I en l'àmbit social?
Si parlem de diners podríem dir: contractem deu persones que ens facin un model des de zero. També podríem demanar-los que s’estudiessin tota la bibliografia que hi ha de models ambientals a escala local, si és que n’hi ha algun i, si no n’hi ha cap, doncs agafem el millor que trobem de cada lloc i fem un model des de zero, molt detallat i extremament ràpid.
D’una banda, potser no serà molt millor que el que tenim ara. I també és veritat que, si tinguéssim recursos il·limitats, podríem mirar, per exemple, d’escalar molt més. És a dir, ara estem fent Barcelona, però podríem fer tota l’Àrea Metropolitana: agafar una gran zona del mapa i calcular-ho amb un clúster superpotent. Podríem portar el model a l’extrem, donar-li molt de detall, fer-lo més gran i fins i tot anar minut a minut.
Però penso que el que estem fent ara és un bon compromís. És clar que amb més recursos es poden fer més coses, això sempre.